
We take a look at how conversational AI improves customer experience by handling uncooperative user behaviour during transactional dialogue.
One of the challenges associated with dialogue state management in task-oriented virtual agents is handling uncooperative behavior while collecting required information from the user in transactional dialogues. These types of dialogue - such as ticket ordering, restaurant booking or money transfer - are more complex than normal intent-based information retrieval, since they usually require the collection of several informational entities and user choices. This means that in addition to predicting the correct initial intent, the conversation state must be tracked over a long series of dialogue steps in order to complete the transaction.
The standard way to manage the conversation in such cases is to initiate what is called a slot filling dialogue - this is where the virtual agent asks the user for each of the required entities (slots) until they are all filled and the dialogue can be completed
An example of a slot filling dialogue, in this case a taxi order, can be viewed in Figure 1. Here, the user triggers a taxi order intent, and initiates a slot filling dialogue where the virtual agent requires a pickup point, a destination and a pickup time in order to make a request to an external service and complete the taxi-order.
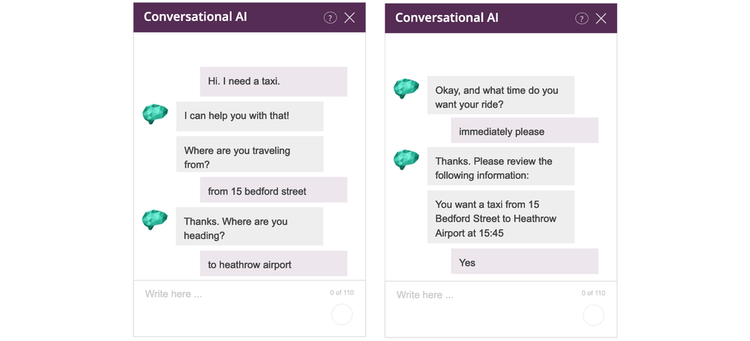
In this example, the user follows what’s known as the happy path and answers the virtual agent’s questions in perfect order. This particular case - where there is no deviation from the happy path - is easiest to handle. The biggest challenges arise when the user is uncooperative with the virtual agent, such as by interrupting the dialogue with a question - i.e. the unhappy path.
This is further complicated in broad scope virtual agents that support a large number of intents across multiple topics. In these cases, the dialogue state has to be tracked in the local context of the conversation, while maintaining the possibility of changing the context in order to answer both related and unrelated questions. When managing a broad scope virtual agent, the problem of variable scope also becomes relevant, since slots extracted in one context shouldn't spill over into others.
Throughout this article, we will dive into some of the challenges with handling uncooperative user behaviour during slot filling dialogues in broad scope virtual agents, and then look at how these challenges are tackled by boost.ai's conversational artificial intelligence.
Finite State Machines
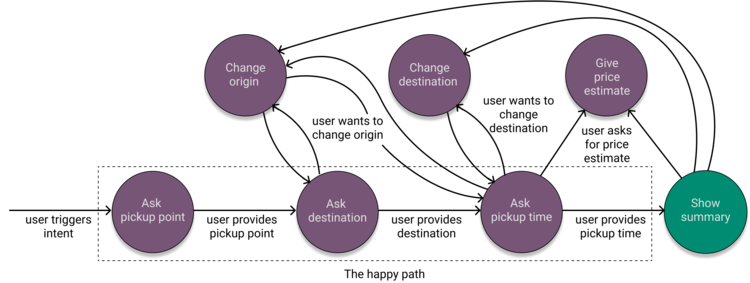
In its simplest form, the slot filling dialogue demonstrated in Figure 1 can be implemented as a Finite State Machine (FSM), consisting of three states. Each of these states has a single transition, triggered when the user provides the requested entity, as per Figure 2.

Assuming that the natural language understanding (NLU) component responsible for entity extraction doesn't make any mistakes, this approach works so long as the user follows the happy path and cooperates with the virtual agent. However, if the user does not cooperate, for example by providing more information than the agent asks for or takes initiative in the conversation by asking a question, this approach breaks down.
There are several ways in which a conversation can deviate from the happy path:
- The user may provide additional information than what the virtual agent asks for (i.e. overinforming)
- The user may want to correct an earlier mistake or change a previous answer
- The user may ask a question related to the current context
- The user may make an intermediate chit-chat reply
- The user may wish to change the topic completely or cancel the current dialogue
These deviations can be further grouped into two categories:
- Overinforming
- User initiative (i.e. when a user wishes to change the direction of a conversation)
While we could include a third category for correction of previous choices, these can be solved on an intent level, and therefore fit under user initiative, as we'll see later.
It's clear that the simple FSM approach pictured above falls short when dealing with these particular challenges, as demonstrated in Figure 3.
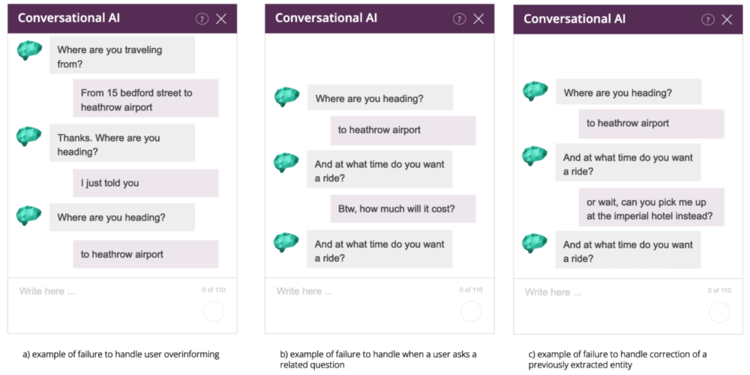
A big issue with the FSM approach is that every state and transition needs to be explicitly defined. It's possible to fix some of the issues listed above by adding new states and transitions. For example, we might create a transition from the state “Ask pickup time” to “Give price estimate” in order to solve example b) in Figure 3. However, since every transition needs to be mapped explicitly, the complexity of the system quickly becomes unmanageable for real projects.
Using forms as an alternative
A solution that solves some of the issues associated with FSMs, while simultaneously abstracting away a lot of the complexity, is using a ‘form’ approach. Instead of explicitly defining the states and transitions, we define a form consisting of each of the required slots.
At every step in the slot filling dialogue, the dialogue manager selects the next required slot from the form that has yet to be extracted and asks the user for that slot. When the user replies, the dialogue manager fills in every entity found by the NLU into the form and repeats this process until all slots are filled.
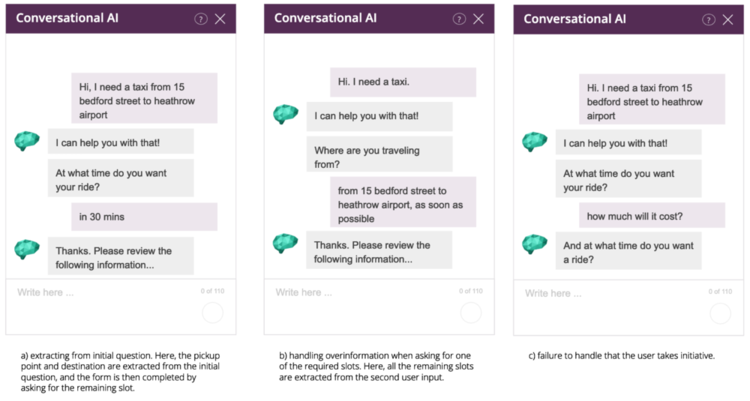
This approach immediately solves the issue of overinforming, as demonstrated in parts a & b of Figure 5. However, it still doesn’t offer a satisfactory solution if the user decides to take initiative, as shown in Figure 5c.
In order to tackle the problem of user initiative during slot filling, we need to take the intent prediction into account. We solve this by combining the intent predictions and entities from the NLU, and deciding - based on the confidences and other scoring measures for each - whether to:
- a) continue the slot filling, or
- b) follow the intent prediction
If the decision algorithm decides to continue the slot filling, the remaining entities found by the NLU are written into the form. We then ask for the next required entity or, if all the slots are filled, move to the next action. If the algorithm decides to use the intent prediction, we leave the slot filling in order to answer the user intent. A high-level overview of this approach can be seen below in Figure 6.
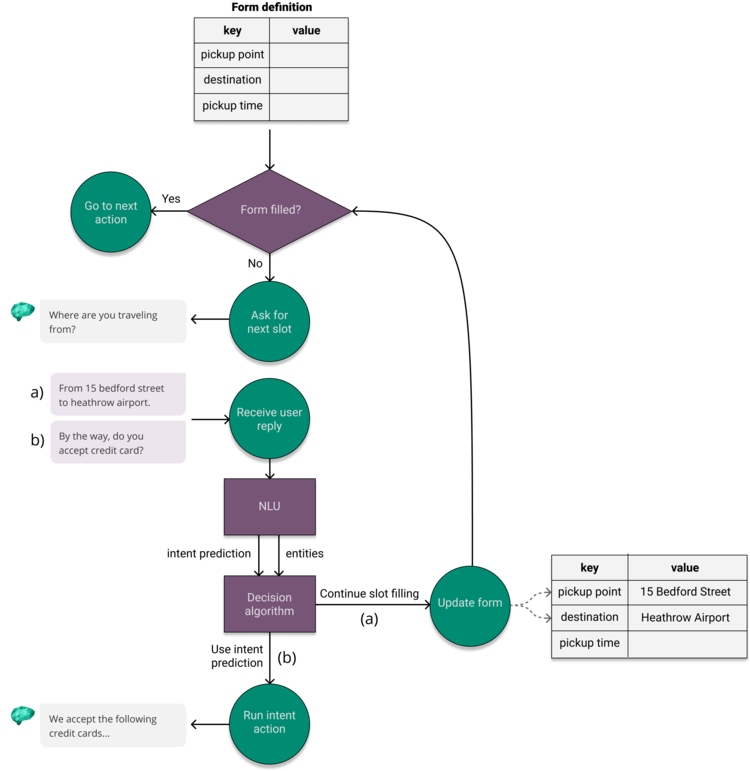
In situation (a), the user responds by overinforming, providing both the pickup point and the destination of the taxi trip. In this case, the decision algorithm decides to continue the slot filling, and the form is updated with the extracted entities.
In situation (b), the user takes initiative of the conversation by asking a related question; whether or not the taxi accepts credit card. In this case, the decision algorithm decides to follow the intent prediction and leaves the slot filling dialogue in order to answer the question.
This approach partly solves the problem of user initiative during slot filling. However, it still leaves us with another issue to discuss, that of variable scope.
Variable Scope
When a user asks a question related to the current context, we want all the collected slots available to pull from when generating an answer. As an example, if the user recently informed us that he or she wants a taxi from Piccadilly to Heathrow, we want these slots available when the user asks for a price estimate for the trip.
However, when developing a virtual agent supporting thousands of intents, we probably don't want the slots available in the global scope (even if this option is technically possible).
As a comparison, imagine a programming project with thousands of files, where every variable in each file belongs in the global scope. If we write to a variable at any place in the code, we affect each one referencing a variable with the same name. It's clear that this would be incredibly difficult to manage for large projects. Which leads nicely into our next topic…
Context
In order to deal with variable scope, we can use context actions.
Context actions allow us to define what intents are relevant to the current context of a conversation. When a context action is visited, it sets an active context on the conversation. When an intent that is part of the currently active context is triggered, any slots that have been collected thus far are passed along to the next action. In effect, all intents listed in the currently active context share the same ‘bucket’ of collected slots.
In addition, context actions let us temporarily map intents to different actions than they would typically map to by default. This makes it possible for a single intent to point to different actions in different contexts. For example, the question ‘How much will it cost?‘ should give a different reply when the user is ordering a taxi than if he or she is applying for a monthly taxi membership.
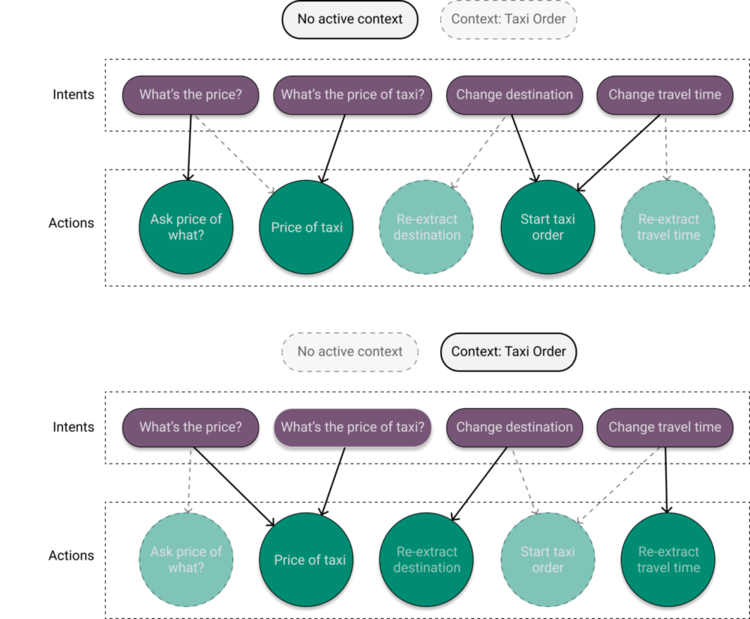
In Figure 7 we see how the active context can temporarily remap what action the intent points to. Note how some actions are remapped in the Taxi Order context, such as the action pointed to by the intent ‘What's the price?’, while others keep their default mapping.
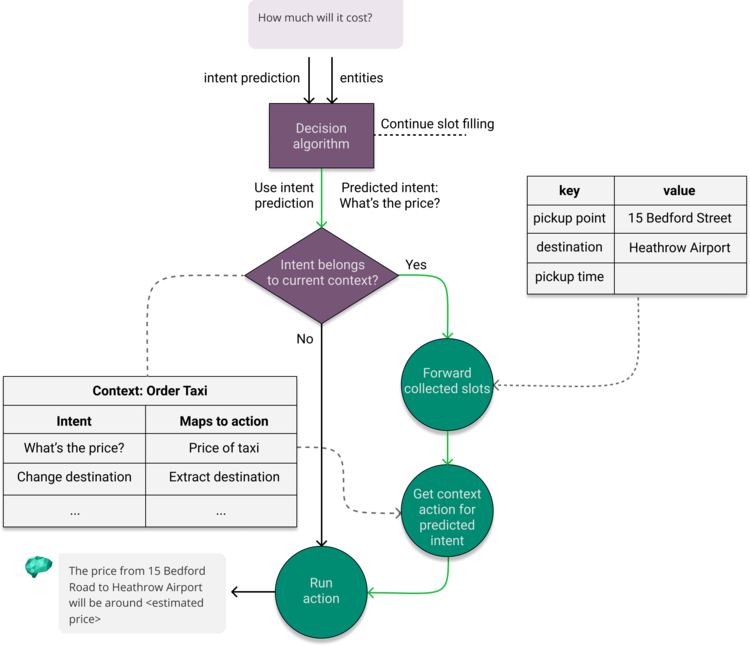
Expanding upon the diagram in Figure 6, Figure 8 shows how the active context is used to determine whether to forward slots to the predicted intent and how the active context overrides the default intent action.
As before, the results from the NLU are forwarded to the decision algorithm with decides whether to either continue the slot filling dialogue or follow through with the intent prediction. If the algorithm decides to go with intent, we then check if the predicted intent belongs in the current context. If there’s a match, we forward the collected slots and execute the action linked to the intent in the current context. If not, the action is executed without forwarding the collected slots. This approach ensures that slots collected in one context do not spill over into others.
This combination of methods allows for conversational AI to support high-quality contextual dialogue. Customers are able to get to the answers they need without being forced to stick to a predefined script, and do so in a manner more in line with a natural conversation - as demonstrated in the example interactions below:
Example 1:

Example 2:
Example 3:
